
Accessing AI without Sacrificing Data Privacy
Accessing AI without Sacrificing Data Privacy
Accessing AI without Sacrificing Data Privacy
The world has understood that AI/ML models need to be trained on a large amount of data to be useful. This means that organizations have rightfully become suspicious of adopting external ML technologies into their workflow for fear of data leakage. Herald has solved this problem by utilizing Retrieval Augmented Generation (RAG) in conjunction with our AI models to prioritize customer privacy while maintaining high levels of performance.
The world has understood that AI/ML models need to be trained on a large amount of data to be useful. This means that organizations have rightfully become suspicious of adopting external ML technologies into their workflow for fear of data leakage. Herald has solved this problem by utilizing Retrieval Augmented Generation (RAG) in conjunction with our AI models to prioritize customer privacy while maintaining high levels of performance.

Understanding the Basics
All ML/AI models interact with customer data at two different times, Training and Deployment.
Training: This point of time when the model memorizes your data to help be able to make future decisions based on the inputs you provide.
Deployment: The model no longer memorizes this data, but it instead makes decisions based on the inputs you provide.
For most ML/AI products, the data from Deployment is fed back into Training to continuously memorize and improve the longer the product goes on. This is why most organizations struggle with adopting ML/AI products as they have various data privacy requirements that would be broken during a continuous training process.
Herald’s solution is unique, as it completely decouples Training and Deployment for our customer’s privacy. Instead, the models we use are trained on the open internet, and our customer’s data is solely used during Deployment. We do so by using RAG to select and filter the best data into the AI/ML model during deployment.
Retrieval Augmented Generation
RAG allows AI models such as Large Language Models (LLMs) (e.g., OpenAI’s GPT/Google’s Gemini) to connect to customer’s data and provide value.
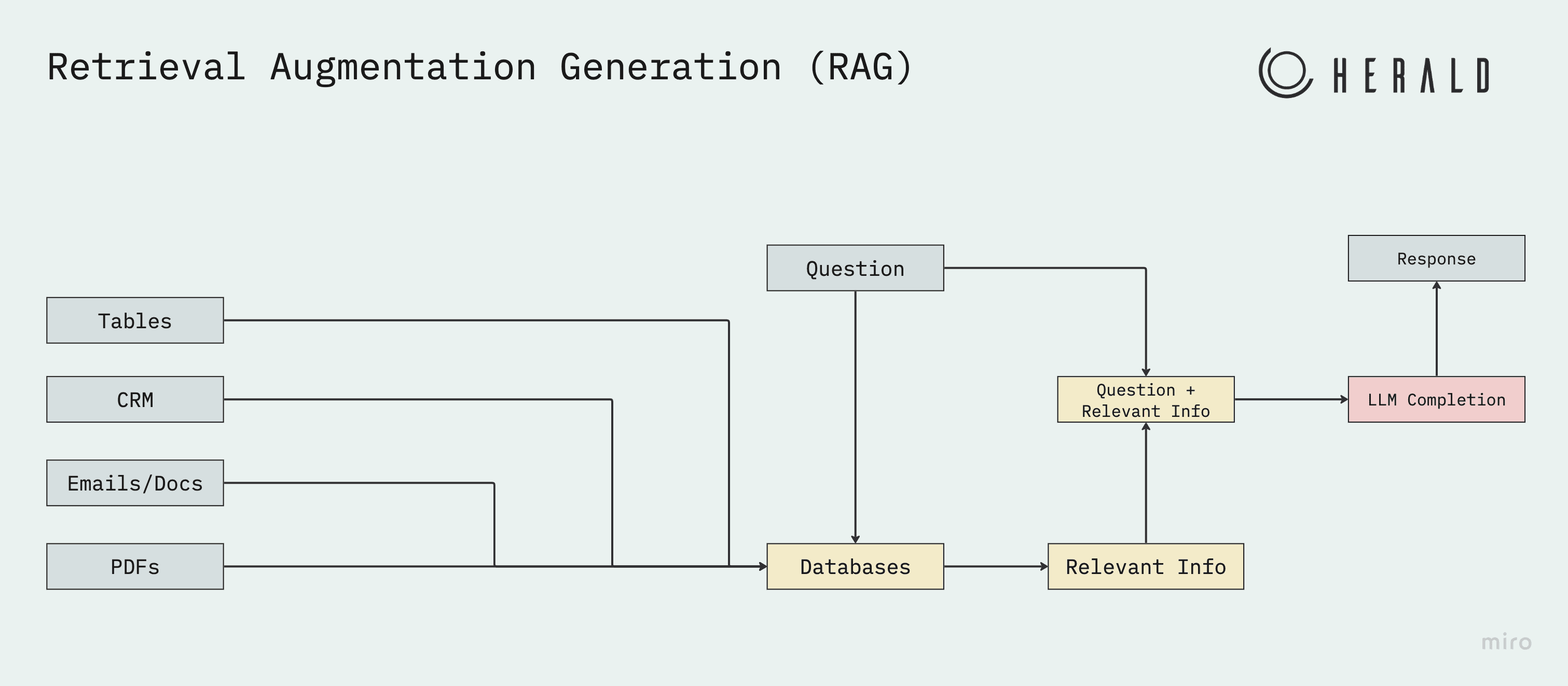
RAG operates in three distinct steps:
Retrieve: Pulls the most important and latest information that can answer the user’s question.
Augment: Combines the retrieved information with the question to augment the user’s question
Generate: Gives the LLM access to the question and the retrieved information to allow it to generate an answer to the question
The core of RAG is in selecting the most relevant information to best answer the user’s question. By constantly selecting the key information, the Large Language Model (LLM) can give best-in-class answers to the user during Deployment while never Training it on the customer’s data.
Conclusion
Herald allows customers to get access to AI tools without needing to worry about data privacy concerns. If you’re interested in our solution, reach out to us via our website or at support@heraldlabs.ai
Understanding the Basics
All ML/AI models interact with customer data at two different times, Training and Deployment.
Training: This point of time when the model memorizes your data to help be able to make future decisions based on the inputs you provide.
Deployment: The model no longer memorizes this data, but it instead makes decisions based on the inputs you provide.
For most ML/AI products, the data from Deployment is fed back into Training to continuously memorize and improve the longer the product goes on. This is why most organizations struggle with adopting ML/AI products as they have various data privacy requirements that would be broken during a continuous training process.
Herald’s solution is unique, as it completely decouples Training and Deployment for our customer’s privacy. Instead, the models we use are trained on the open internet, and our customer’s data is solely used during Deployment. We do so by using RAG to select and filter the best data into the AI/ML model during deployment.
Retrieval Augmented Generation
RAG allows AI models such as Large Language Models (LLMs) (e.g., OpenAI’s GPT/Google’s Gemini) to connect to customer’s data and provide value.
RAG operates in three distinct steps:
Retrieve: Pulls the most important and latest information that can answer the user’s question.
Augment: Combines the retrieved information with the question to augment the user’s question
Generate: Gives the LLM access to the question and the retrieved information to allow it to generate an answer to the question
The core of RAG is in selecting the most relevant information to best answer the user’s question. By constantly selecting the key information, the Large Language Model (LLM) can give best-in-class answers to the user during Deployment while never Training it on the customer’s data.
Conclusion
Herald allows customers to get access to AI tools without needing to worry about data privacy concerns. If you’re interested in our solution, reach out to us via our website or at support@heraldlabs.ai
Understanding the Basics
All ML/AI models interact with customer data at two different times, Training and Deployment.
Training: This point of time when the model memorizes your data to help be able to make future decisions based on the inputs you provide.
Deployment: The model no longer memorizes this data, but it instead makes decisions based on the inputs you provide.
For most ML/AI products, the data from Deployment is fed back into Training to continuously memorize and improve the longer the product goes on. This is why most organizations struggle with adopting ML/AI products as they have various data privacy requirements that would be broken during a continuous training process.
Herald’s solution is unique, as it completely decouples Training and Deployment for our customer’s privacy. Instead, the models we use are trained on the open internet, and our customer’s data is solely used during Deployment. We do so by using RAG to select and filter the best data into the AI/ML model during deployment.
Retrieval Augmented Generation
RAG allows AI models such as Large Language Models (LLMs) (e.g., OpenAI’s GPT/Google’s Gemini) to connect to customer’s data and provide value.
RAG operates in three distinct steps:
Retrieve: Pulls the most important and latest information that can answer the user’s question.
Augment: Combines the retrieved information with the question to augment the user’s question
Generate: Gives the LLM access to the question and the retrieved information to allow it to generate an answer to the question
The core of RAG is in selecting the most relevant information to best answer the user’s question. By constantly selecting the key information, the Large Language Model (LLM) can give best-in-class answers to the user during Deployment while never Training it on the customer’s data.
Conclusion
Herald allows customers to get access to AI tools without needing to worry about data privacy concerns. If you’re interested in our solution, reach out to us via our website or at support@heraldlabs.ai
Schedule a call with the Herald team
Schedule a call with the Herald team